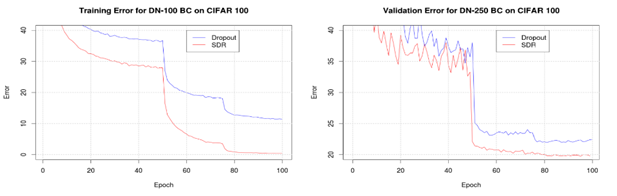
Graphs comparing the use of SDR vs. Dropout. SDR has significantly less training and validation errors.
SInvention Summary:
Deep learning has enabled advances in text, image and speech analysis and processing. The deep layered neural networks necessary for these activities lead to high-dimensional, nonlinear parameter spaces that can prove difficult to search and lead to overfitting, model misspecification and poor generalization performance.
Rutgers researcher, Dr. Stephen Hanson, has developed a solution named the Stochastic Data Rule (SDR) that addresses these problems and improves on existing algorithms for training deep learning neural networks. SDR promises faster, more accurate deep learning by injecting noise in the weights that reflect a local history of prediction error and local model averaging causing the hidden unit attached to each weight to change adaptively as a function of the update’s error gradient. This process provides a more sensitive local gradient-dependent simulated annealing per weight has a global effect on network convergence, providing efficiency improvements.
Testing against the Dropout algorithm, a well-known solution for overfitting, SDR shows validation error improvement of 13% and improvement of training error of 80%. Moreover, SDR can scale to 100+ neural layers, thousands of hidden units, and millions of deep learning weights. By reducing training error and validation error, SDR allows for the same level of training accuracy as Dropout in as little as 40 training epochs to Dropout’s 100 training epochs. In addition, when compared to Dropout, SDR reduces training time for deep learning by 58%. Apart from the huge improvement in efficiency in training and better validation data.
Advantages:
- A state-of-the-art method for training deep learning neural networks.
- Better performance than the well-known Dropout algorithm.
- Easy to use, requiring only 50 lines of code.
Market Applications:
Artificial Intelligence based applications that train deep learning neural networks (e.g., ones that use speech recognition, computer vision, and image analysis) used in wide range of industries including automotive, robotics, healthcare & medicine.
Publications:
N. Frazier-Logue and S. J. Hanson, "The Stochastic Delta Rule: Faster and More Accurate Deep Learning Through Adaptive Weight Noise," in Neural
Computation, vol. 32, no. 5, pp. 1018-1032, May 2020.
Intellectual Property & Development Status:
The technology is patent pending and is currently available for licensing.
