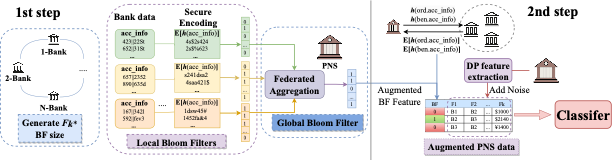
2-step overview of the method
Invention Summary:
Predictive analytics are essential for optimizing industrial processes, but distributed sensitive data lacks generalizability, suffers from bias, and can't be gathered centrally. Although federated learning and privacy-preserving methods solve data mining problems, they face scalability and utility issues.
Rutgers researchers developed an (International award-winning) efficient, scalable, and secure method for validating distributed sensitive data and federated learning. It uses a novel encoding scheme based on symmetric key encryption, cryptographic hash functions, pseudorandom function, and bloom filters to create a new differentially private dataset for machine learning models and data analytics. This approach enables multiple organizations to collaborate on data-driven solutions while maintaining data privacy and security.
Market Applications:
- Secure and privacy‐preserving input (e.g., bank/patient account information) validation.
- Secure feature mining (from sensitive data that is distributed)
- Federated anomaly (e.g., financial crime) detection
Advantages:
- No noteworthy drop in accuracy between the federated and the centralized setting.
- The approach is extremely flexible, that is, it can easily be incorporated into existing or new machine learning /AI models.
Intellectual Property & Development Status: Patent pending. Available for licensing and/or research collaboration. For any business development and other collaborative partnerships, contact marketingbd@research.rutgers.edu.