Learning without sharing medical images

Segmentation using synthetic images
Invention Summary:
Large volumes of data are necessary to train machine learning (ML) algorithms (especially for medical image analysis.) HIPAA and other privacy regulations make it difficult to obtain sufficiently large volumes of disease related images (e.g., from different medical institutions) necessary for training machine learning models used in artificial intelligence (AI) based medical applications or medical analysis purpose.
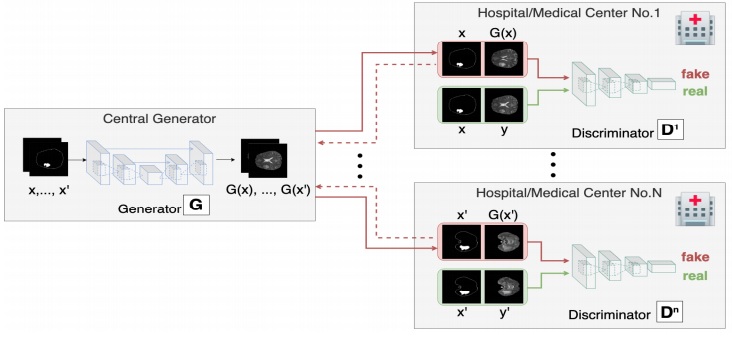
Rutgers researchers have developed a data privacy-preserving and communication efficient distributed generative adversarial neural network (GAN) framework, referred to as Asynchronized Discriminator GAN (AsynDGAN), which resolves this problem by generating synthetic images for use in ML. The framework trains a central generator that creates the synthetic images by learning from one or more distributed discriminators. AsynDGAN can be used to generate (medical) images for training task-specific models without the need to access or store private patients’ data.
The framework has been validated on different datasets and demonstrated that a model trained solely by synthetic data has competitive performance with models trained by real data, and that it outperforms models trained locally, in each medical entity.
Advantages:
- A data privacy-preserving mechanism for access to sensitive data
- Adaptive to technology architecture updates
- Better communication efficiency and requires lower bandwidth
- Able to be used for non-medical applications
Market Applications: Any industry restricted by privacy rules and requiring enormous data sets in multiple physical locations for training ML algorithms, such as healthcare, automotive and financial industries.
Intellectual Property & Development Status: Patent Pending. Available for licensing and/or research collaboration.
