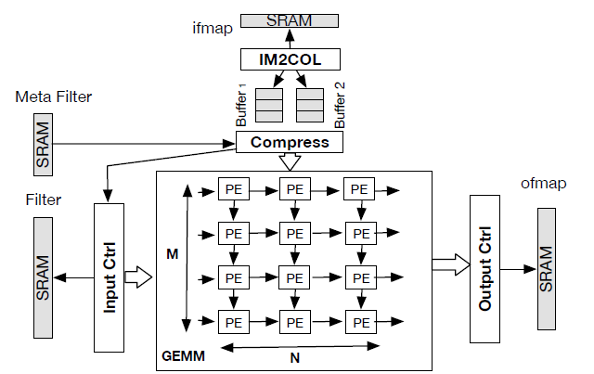
The overall architecture of the accelerator with the Im2Col unit and a systolic array based GEMM unit
Invention Summary:
Neural network is widely used in numerous domains such as video processing, speech recognition, and natural language processing. It includes the training phase which is performed in the cloud or on a larger cluster of machines and an inference phase which is usually performed on the edge devices, which typically have limited memory and compute resource with strict requirements on energy usage.
Rutgers researchers have developed a novel hardware accelerator- SPOTS, for inference task with sparse convolutional neural networks (CNNs). This hardware unit performs Image to Column (IM2COL) transformation of the input feature map coupled with a systolic array based general matrix-matrix multiplication (GEMM) unit which maximizes parallelism and improves energy efficiency and latency by streaming the input feature map only once. The sparsity awareness of this accelerator improves the performance and energy efficiency by effectively mapping the sparsity of both feature maps and filters. The dynamic reconfigurability of the systolic array based GEMM unit enables effective pipelining of IM2COL and GEMM operations and attains high processing element (PE) utilization for a wide range of CNNs.
Advantages:
- Compared to prior hardware accelerators, SPOT is, on average 2.16x, 1.74x, and 1.63x faster than Gemmini, Eyeriss, and Sparse-PE.
- SPOTS is 78x and 12x more energy-efficient compared to CPU and GPU implementations, respectively.
- Sparsity awareness of this accelerator improves the performance and energy efficiency by effectively mapping the sparsity of both feature maps and filters.
Market Applications:
Artificial Intelligence Accelerator can enhance the performance of:
- Cyber- security
- Automotive & Manufacturing
- Internet of Things and Robotics
- Healthcare
- Agriculture
Intellectual Property & Development Status: Patent pending, available for licensing and/or research collaboration.
